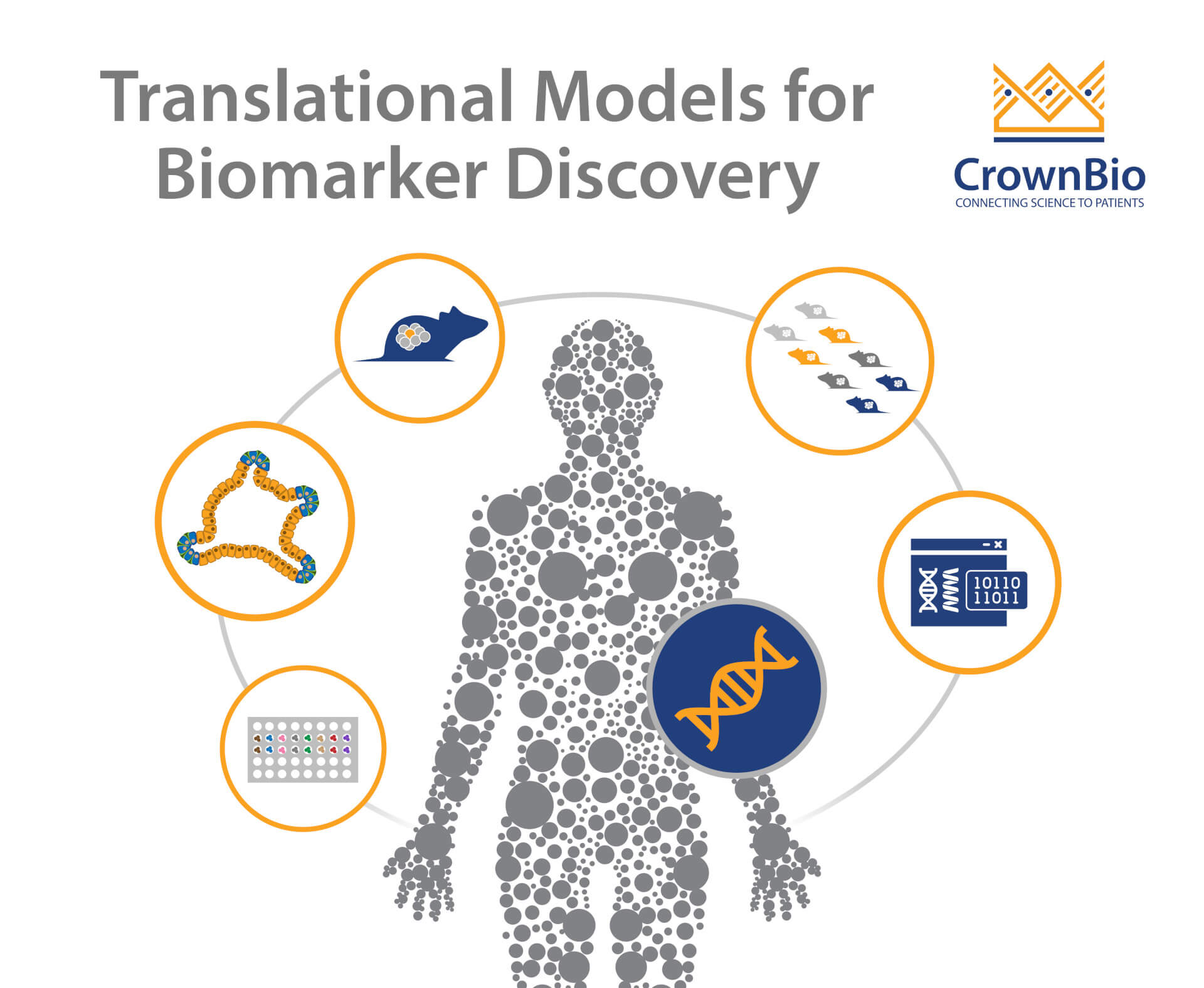
Explore a variety of methods to identify predictive biomarkers using a range of translational preclinical models combined with robust analytical methods.
New strategies are needed to overcome the high attrition rates of anticancer agents in clinical development. One such method is to develop and validate robust and sensitive biomarkers early in the drug development process.
This allows researchers to gain in depth insights into agent’s mechanism of action and pharmacodynamic response. This then allows the most promising candidate therapies to be identified, and novel therapeutics to be tailored for specific patient populations and cancer indications, right from the earliest stages of development.
Early identification of biomarkers also helps to optimize clinical trial design through data informed decisions. Biomarkers identified early in preclinical development can be translated into the clinic as companion diagnostics (CDx), to stratify relevant patient populations for treatment.
These biomarker-driven approaches are fueling precision medicine to improve drug efficacy, patient safety, and to reduce the attrition rate of anticancer agents.
How to Identify Predictive Biomarkers Early in Oncology Drug Development
The key to early identification of biomarkers is to embed a systems biology approach early in drug development. This allows researchers to funnel therapeutics through in silico, in vitro, ex vivo, and in vivo models in an efficient way, reducing development timelines and maximizing data use. Optimal targets and preclinical models can then also be chosen and used.
To make all of this possible, you need access to large panels of highly characterized preclinical models, which fully capture the diversity in the oncology patient population. This then allows biomarker discovery from a range of different studies/model types including in vitro screening, unique in vivopatient-derived xenograft (PDX) models, and mouse clinical trials (MCTs).
Identifying Predictive Biomarkers from In Vitro Screening
One method to identify biomarkers is through in vitro screens, using cancer cell line panels or, more recently, tumor organoids. These screens are usually preliminary, followed by more in-depth functional and mechanistic in vivo studies.
Using large panels of well-characterized cell lines or organoids and a range of analyses it’s possible to gain an understanding of genetic signatures of response, and develop biomarkers to guide future in vivo model selection. This is achieved by correlating pharmacology screening data with genomic baseline information, such as gene expression, gene mutation, and copy number variation data as well as pathway/network activation information.
Multiple readouts from analyzing these screens include:
Single gene analysis – identifying single genes whose mutational status correlates with sensitivity.
Composite biomarker generation – constructing multi gene biomarker sets which predict sensitivity to an agent.
Pathway/network analyses – identifying signatures composed of gene sets/pathways that significantly differentiate sensitive and insensitive cell lines.
Overall, in vitro screening for biomarker discovery provides multiple tracks of unbiased, data driven statistical analysis for gene mutations, expressions, and in pathways. This lets you derive potential candidate biomarker sets to choose the right indication for your agent, and for early patient selection criteria.
Using PDX Models to Uncover Drug Mechanism of Action
Highly translational preclinical models can hold the key to confirming a drugs mechanism of action, which can corroborate clinical observations and provide prognostic biomarkers for the clinic.
Many targeted agents are highly useful for only small groups of patients – those with a specific genetic event like a mutation or fusion. These original genetic events are often lacking in in vivo models such as conventional cell line derived xenografts, as well as the later genetic driver events behind the acquired resistance common with targeted agent treatment.
When looking to confirm drug mechanism of action, clinical observations, or to study clinical resistance mechanisms, PDX models can be highly useful. PDX are derived directly from patient tumors (never adapted to grow on plastic), and therefore retain many features of human tumors including parental tumor histopathology and genetics. Large panels of PDX have now been characterized and collated in databases, making it easier to find clinically representative models with fairly rare or unique genetic features of interest.
These clinically relevant models are used as a first step in confirming agent activity against a genetic event, potentially compared against standard of care. This corroborates if your new drug is active against the mutation or fusion that you are targeting, confirming drug mechanism of action.
For assessing targeted agent resistance, some PDX have been developed directly from patient tumors, or other relevant models can be generated. By starting with a model harboring one genetic event, extended treatment with your agent or standard of care can generate a drug resistant model. Through sequencing, the genetic events leading to resistance can be confirmed. Agents can then be trialed to overcome this resistance and see how they perform against multiple molecular events.
Overall, using highly clinically relevant PDX models and generating resistance models as needed can confirm drug mechanisms of action. By thoroughly understanding these truly translational models, they can be used to corroborate clinical data and understand clinical trial design. Uncovering molecular events behind drug response/resistance can also provide prognostic biomarkers to predict clinical response.
Using Hypothesis-Free Biomarker Discovery to Optimize Clinical Trial Design
Hypothesis-free biomarker discovery is as the name suggests – using a variety of tools in a systematic and empirical pipeline to uncover biomarkers potentially without any knowledge of the drug or mechanism of action being investigated. This approach is also not limited by patient heterogeneity.
The main goals of hypothesis-free biomarker discovery analyses are to:
Understand true mutations from variants
Determine the functional effects of genetic aberrations
Understand deleterious effects at the DNA, RNA, and protein levels
Identify the most appropriate indications and target patient populations.
For understanding patient populations, this can help to optimize clinical trial stratification when a drug is already in the clinic by retrospectively analyzing biomarkers.
A key first step in this approach is often to run a mouse clinical trial (MCT). MCTs are population studies - surrogate clinical trials in a preclinical setting, capturing the clinical heterogeneity. They replicate clinical trials using PDX models, with the added advantage of including multiple replicates of the same patient in each arm.
For hypothesis-free biomarker discovery, multiple PDX are screened to generate response data which is correlated with characterization data. Advanced statistical frameworks have already been designed for MCTs to maximize the studies for efficacy evaluation and biomarker discovery.
Through analyzing the MCT data, biomarker panels are identified based on features such as gene expression or mutation. These panels can be compared with current clinical trial enrollment criteria to see if these are optimized or can be adjusted. Overall, this can improve the accuracy of patient stratification and clinical trial enrollment, potentially leading to expanding drug indications or opening trials to larger groups of relevant patients.
Other benefits of MCT/in silico analyses include rescuing and repurposing previously “unsuccessful” investigational agents, and to increase success rates and trial accuracy through in depth, big data analysis.
Conclusion
Early identification of predictive biomarkers during preclinical drug development provides a wealth of benefits, ultimately offering multiple opportunities to de-risk clinical trials.
Optimal platforms for biomarker discovery are established by implementing systems biology approaches, and leveraging a variety of preclinical models combined with robust analytical techniques. This accelerates drug development, and hopefully leads to improved chances of clinical success.
Advancements in oncology are increasingly driven by the ability to extract more detailed and precise information from patient tumor samples. Tradition…
Oncology continues to be a rapidly changing field with scientific discoveries transforming patient treatment and care. As it stands today, advancement…
Cancer research has evolved significantly over the years, driven by the need for more precise and efficient methods to study tumor biology, identify b…